
Why I don’t use Docker much anymore
Introduction

Update: The conclusion of this post talks about managing Docker kittens with Ansible; I no longer do that, but instead use Amazon ECS with Terraform. Docker has stabilized a lot since my early experiences as well. However some things like custom kernel parameters (e.g. for Redis) will always be a limitation. I’ll write a new blog post on how I use ECS and Terraform soon.
When I first started using Docker about a year ago for developing Rails applications, I had dreams of using it across all development environments (development/test through production) and in all related services (linked containers consisting of application servers, databases, in-memory caches, search indexes, etc.). I mean, why wouldn’t you - not only would you get more thorough guarantees of your code and systems matching what production’s running, but you are getting the high performance of containers over VMs when developing! And a year ago it seemed like it wouldn’t be long until the problem of easily deploying these linked containers across multiple hosts would be solved.
However, in time, I gave up on both aspects of Docker use. Now I only use Docker to build a sort of “gold master” Docker image of my Rails application on a CI server, which gets tested in a remote staging environment and deployed to production (my last blog post explains the process of how I use CircleCI for this). I don’t use Docker for any of the other services (Postgres, Redis, Elasticsearch, RabbitMQ, etc.). I also don’t use Docker for local development or testing anymore.
So what happened?
Giving up on Docker in development
Most of the problems with Docker in development are really my own fault, trying to contort Docker into this use case. As I detailed in my first post on Docker for development, I use Linux as my host OS and used Vagrant for container orchestration (nowadays docker-compose - formerly fig - would be preferable, but at the time Vagrant was better as it would autoload a boot2docker VM when necessary). These were some of the things I bumped into which made me abandon ship:
- Difficult to do terminal multiplexing (have multiple terminals open) in a single container, e.g. a Rails console and a Rails server. Could possibly run tmux or screen or use nsenter but I gave up before trying anything like that.
- Having to run
bundle installevery time I spin up a new container to install development/test gems. This is because my images are always built for production use by default, sodevelopment/testgroup gems have to be installed when a new container is brought up. - File ownership issues when using bind mounts. If the UID on your host system doesn’t match the UID of the user inside your Docker container, you will have file ownership issues. I think most people don’t encounter this because they are probably the only user on their development machine, and most people only add a single user in their Dockerfile to run their app. I’m not sure about other Linuxes, but Ubuntu will assign the first user a UID of 1000 so if you’re the first user on an Ubuntu host and you have an Ubuntu-based Docker image, you won’t even notice. This was really confusing for me back in the day; advice I was given is to avoid host volumes (which is good advice where possible):
@abevoelker withcontainer-to-container volumes if you control the image on both sides, usually a non-issue. Avoid host volumes if you can :)
— Solomon Hykes (@solomonstre) July 30, 2014- Difficulty interfacing with the host machine’s notification message bus (e.g. libnotify) for showing test suite failures (e.g. from guard). Could maybe be done by setting up complicated proxies, but I didn’t find it worth the effort.
- Inability to open host browser windows from gems like
launchy. For example, gems likeletter_openerwhich opens a browser tab for previewing emails (I’ve since switched toletter_opener_web) or Capybara’ssave_and_open_pagehelper for debugging view or feature spec issues. - Issues with development server IP not matching host IP. For example, the new web-console in Rails 4.2 (or better_errors in older Rails versions) provides a live Rails console when your development server hits a runtime exception, but the feature is whitelisted (for good reason) to
localhostaccess only. Since your host IP doesn’t match the interface the Rails server is bound to (on Docker), you don’t get the live shell without some additional configuration.
Giving up on multi-host container linking / Dockerizing every service
There are two main reasons I gave up on Docker for all the services.
The first is that some services just don’t easily lend themselves to Dockerizing. For example, I spent a lot of time on creating a Postgres Docker image that includes some language extensions as well as WAL-E for handling backups to S3. The problem is that to do periodic base backups, I needed cron to run in the same process space as the Postgres postmaster process (WAL-E needs to communicate with Postgres via IPC). And then cron apparently requires syslog to be running, so I had to try and get that running as well. But then to get error messages, I also needed an MTA running, and then I hit a weird bug trying to set that up…
And then I spend hours trying to debug cron because silent setgid restrictions in my Docker version mess up Postfix https://t.co/i3Q7lui2Z5
— Abe Voelker (@abevoelker) July 31, 2014And then after getting all that working, in order to provide configurable cron jobs, I’d have to either bind mount a directory from the host into /etc/cron.d/, which gets into the aforementioned bind mount issues again, or create another container and mount it using --volumes-from, which gives me another container I have to manage the lifetime of. To support bind mounts, I had to create an ENTRYPOINT wrapper script which would ensure permissions are set properly on files before running Postgres, which also seems to be the way that official Docker images handle the problem (see official Postgres and MongoDB images).
Eventually to get around the cron issues, I ended up just using Phusion’s baseimage-docker (disabling SSH though), because they’ve already spent time working around the Dockerisms that cause these weird problems, and cron and syslog just work out of the box (I cautiously noted that team Docker has some issues with this image (1, 2)). But then, since I realize that I’m going to give Postgres its own box anyway for proper resource utilization, I realize that I’ve really gained nothing by Dockerizing it.
Instead I had only added complexity by using Docker, as now I was in charge of building a complex Docker image with its own process manager inside the container (which is typically a pretty big red flag), including how to handle those processes dying (nowadays I’d recommend this approach using S6). As well as now having to manage the Docker daemon process on the host (including updates), lifetimes of Docker containers and images on the host machine, and a process manager on the host for restarting the Docker container and/or Docker daemon if they fail. Not to mention some other complexity of Docker containers that I’ll get to in my next post, like how to manage logging or the potential for orphaned Docker images and stopped containers to fill up disk space.
The second reason is that for my applications, I didn’t find a compelling advantage to linking the containers across hosts, especially given the complexity requirements. There is a pattern advocated called the ambassador pattern, but that just adds a layer of indirection by pushing the cross-host interconnect information into additional Docker containers (the advantage is in getting around --link’s static-ness). Lots of people seem to reach for service discovery tools at this point like etcd, Consul, SkyDock, whatever. Another solution would be to use Docker Swarm or weave, which seem to make multiple Docker hosts appear as if they were one (remote containers see eachother as being managed by one daemon), but these are (or were) pretty bleeding edge at the time.
Since my application is pretty simple and my services get their own boxes (I’m not dealing with a really dynamic environment), I decided it was easier to just make my Dockerized services accept remote host information as environment variables, and pass them in with -e / --env-file. So in other words, just expose them like any other remote service.
This whole experience sort of brought me to this conclusion:
Simple multi-host Docker applications are not an ecosystem focus
Instead, the Docker community seems more focused on handling the very large scale deployments, with cluster-oriented tools like Kubernetes, CoreOS+fleet, Centurion, Helios, Mesos, Serf, Consul, etc. and Docker’s creation of libswarm, which was originally a standard interface for some of these tools (it seems to have morphed into something more since I last checked and is just called “Swarm” now).
Another way of saying it is that Docker is more focused on the “cattle” perspective of service topologies rather than “kitten”:
Cattle vs Kittens
Kittens are pets. Each cute little kitten has a name, get stroked every day, have special food and needs including "cuddles." Without constant attention your kittens will die. ... Everyone gets upset when a kitten dies.
The other type of application is "Cattle." Cattle live outside in a field, mostly look after themselves for days on end, have numbers instead of names and farmers manage cattle in herds. There may are hundreds or even thousands of instances in the "herd" that exist somewhere in the data centre but no one much cares about them. If they sicken or die, someone will get to them eventually. Probably with a big tractor and zero ceremony.
— Greg Ferro Cattle vs Kittens – On Cloud Platforms No One Hears the Kittens DyingCattle topology visualized (slide taken from an Apache Mesos talk):
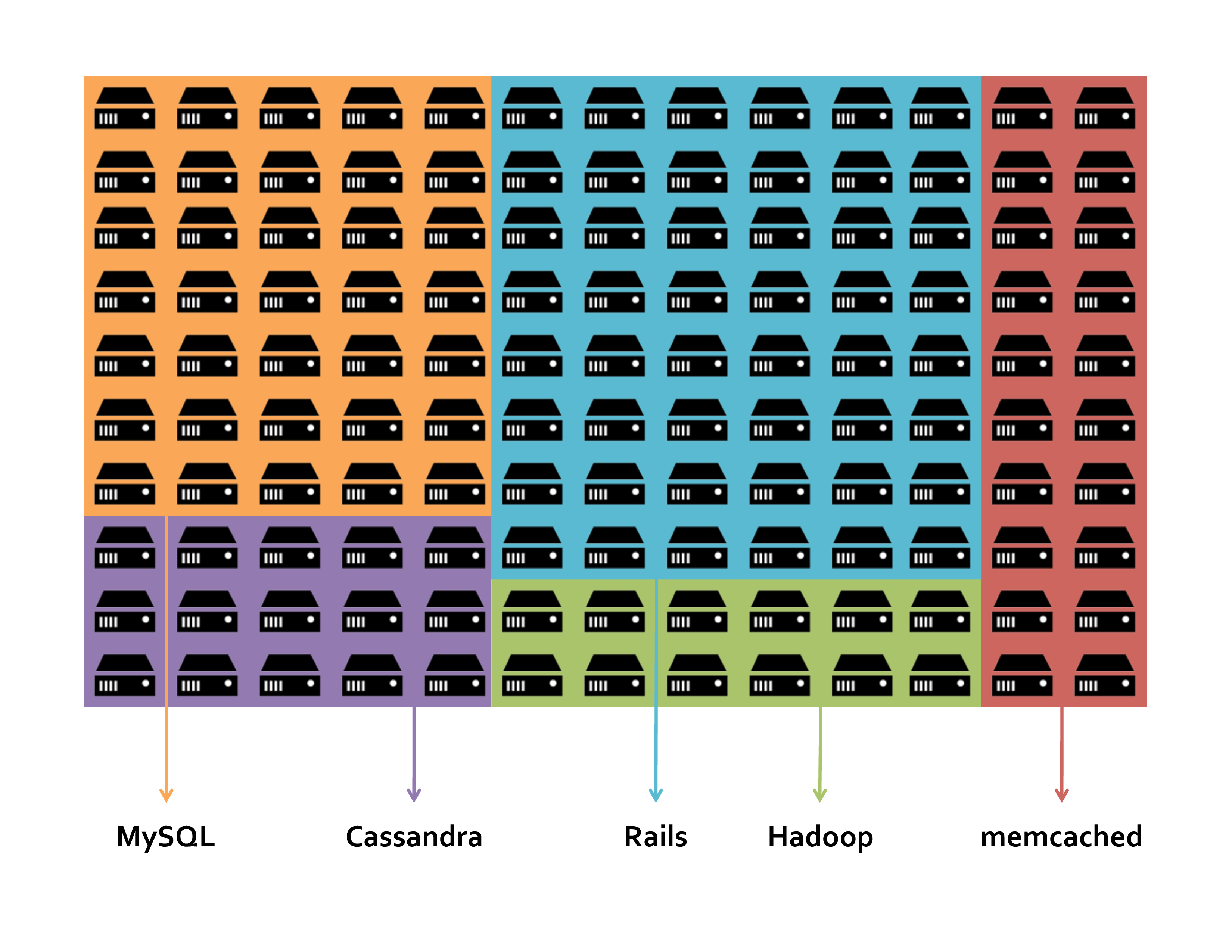
The cattle topology requires that the services being managed are horizontally scalable - that is, every colored node in this diagram is equivalent to a node of the same color, and can be easily scaled up or down by adding or removing nodes from the cluster. And some nodes suddenly disappearing don’t drastically impact the overall service - notice you don’t see any precious snowflakes in this diagram.
The cattle topology is required for services that need to be resistant to downtime, so companies that can’t afford such downtime (Google, Amazon, etc.) will spend the effort ensuring their services fit this pattern. But the problem is that not all services are easily amenable to this; oftentimes tradeoffs have to be made and it may require a lot of programmer effort to put it through a chop shop to enact those choices.
For example, while application servers fit pretty easily into this paradigm as they are (or should be) stateless, relational databases tend not to. Postgres specifically is not super easy to configure for this; there are ways to do high availability (HA) with Postgres using replication, yielding a master and hot standby slaves, but there’s no standard formula for it. There are also exotic solutions like Postgres-XC which give you multi-master, but with a reduced feature set (so complex in a different way). Conveniently, the Mesos diagram lists MySQL, which is an exception to this rule as it comes with multi-master baked in. And other services, like Redis, have only relatively recently gotten horizontally scalable features (Redis Cluster).
Speaking of Redis, Redis needs custom kernel tweaks in production (namely transparent huge pages disabled). The problem with that in terms of Docker usage is that Docker containers share a kernel, so any change in kernel params will affect every Docker container on that system. So if you have conflicting parameters, you now need to manage container allocations on specific VMs.
I can totally understand why Docker would focus on this side of things, and solving it in the big picture will probably lead to solutions that also trickle down to those of us with the smaller use cases (eventually). But in the here and now, it feels like there is a still a gap for my use case if I don’t want to fit all my application services into a Docker cluster.
So in the meantime, I guess I’ll have to just keep herding my kittens in the traditional way:
Giving up on Docker in general: death by a thousand papercuts
"I think we're at 9 5's currently (with Docker)
55.5555555% uptime"
— ηθικός αλχημιστής (@bitemyapp) September 25, 2014I debated whether I should write this section or not, because I think the people that work on Docker are all really nice and they’ve been very helpful on IRC, GitHub, Twitter and HN from all of my experiences. That includes Solomon Hykes, creator of Docker, who has interacted with me several times on Twitter - it’s clear he’s a really nice and helpful guy. So I hope I don’t hurt anyone’s feelings with this.
And hell maybe it’s really all my fault anyway (my coworker thinks I have some kind of Docker-bug-finding-aura, particularly when I deadlocked the Docker daemon with unexpected flags passed to docker ps), or just what you get when you start playing with a technology while it’s still young.
But I have to be honest in saying that when I weigh my entire one year experience with Docker, I’ve found it to be somewhat unreliable. Six months ago if I were having trouble with something Docker-related I would honestly feel like there was a 50/50 chance between it being my fault or a Docker bug/limitation.
To be fair though, I think that there has been a focus on shoring up stability in recent Docker releases (specifically, the last few months). 1.4 and up definitely feel more solid to me; the majority of my experience with Docker is with 1.3 and earlier.
But even now I’m running into a really bad issue where my host machines completely lock up due to Docker STDOUT logging causing some kind of memory leak:
Apparently Docker containers logging to STDOUT causes memory leak leading to lockups. NEAT! http://t.co/2xeKeS8ohc pic.twitter.com/YG6XlTt44N
— Abe Voelker (@abevoelker) February 13, 2015I have to go in to my DigitalOcean panel to hard restart the machine because the memory leaks cause SSH to become unresponsive. And I still encounter weird one-off issues time to time (this was a one-off random error on 1.4):
Holy shit Docker wtf r u doing pic.twitter.com/nkdMBcTPxZ
— Abe Voelker (@abevoelker) February 13, 2015If it’s something I can reproduce, I will of course file an issue (and the Docker team have been good about fixing problems or alternatively telling me why I’m dumb / doing it wrong). But sometimes it would just be a fleeting error that doesn’t happen when I try again. Or sometimes I’d have to restart the Docker daemon, and then it works. But let’s just say my friends could historically tell when I was working on my side project over the weekends based on the number of tweets cursing Docker.
Maybe if I was just starting using Docker today, on recent Docker versions, I wouldn’t feel this way. Or maybe if I had been running a huge cluster of containers, as Docker is probably intended for, I wouldn’t have really cared/noticed because the misbehaving containers and/or hosts would’ve gotten trashed and recreated from a clean state in the background.
But today, if Docker comes up in conversation I find myself telling people to avoid it for basic usage unless there’s a very clear win (for now anyway - I tell them to wait a while yet).
Not giving up on Docker completely
I still use Docker for one singular reason: deploying Rails applications is still hugely messy, and Docker is good at containing that mess. In other words the complexity of introducing Docker is less than the complexity of managing a Rails app’s dependencies (Ruby interpreter, 3rd party libs like libxml2 or ImageMagick, asset pipeline compilation, nginx, etc.) and how those dependencies mutate over time. Compared to the other services, the Ruby application servers do mutate quite a bit over time so it’s advantageous to bundle them up into immutable Docker images.
Some may be wondering why I don’t just use Heroku or similar PaaS if I only am using Docker for Ruby/Rails application servers. It’s mainly due to cost. The side project I’m working on is on a limited budget (a subset of my own personal budget), and it would cost a lot of money for all the services I need (Postgres, Elasticsearch, Redis) as well as the dyno cost for two application dynos + the background workers. If I use a VPS like DigitalOcean or Linode I’m paying less than 1/3 the cost of running all these services on the Heroku/EC2 ecosystem.
Docker will get there eventually
I have no doubt that in time Docker will make my use case more feasible, probably once tools like Swarm, Kubernetes, et al. congeal. There’s simply way too much momentum and capital behind it for it not to inevitably do so.
So even though Docker didn’t end up cutting the gordian knot of my deployment issues like I had hoped, I’m still rooting for it. I think a lot of us developers are, which is why Docker gets so much love. We all want to be doing programming, not shaving DevOps yaks all day. But the current reality for me is that Docker just isn’t quite there yet in all the ways I’d hoped.

I have one last Docker blog post in the pipeline, which will deal with how I deploy Rails Docker containers as “kittens” using Ansible. Including zero-downtime rolling deploys using the awesome HAProxy load balancer and Ansible’s serial and wait_for state=drained features.
Thanks to Chris Allen for reviewing a draft of this post.