
Rails Development Using Docker and Vagrant
Introduction

If you’re like me, you’ve probably been hearing a lot about Docker over the past year but haven’t really gotten past the “hello world” tutorial because you haven’t found a good way to integrate it into your development workflow or staging/production deployment process. I’ve spent the last several weeks learning Docker and porting a Rails project’s development environment from Ansible provisioning to Docker, so I thought I’d share my experiences so far.
Why Docker?
Until recently I had been pretty happy with my development provisioning setup, which consisted of Vagrant for spinning up development machines and Ansible playbooks for provisioning the software I needed installed on them. Eventually, after getting sick of the slowness of virtual machines (Vagrant’s default provider is VirtualBox), I switched to the excellent vagrant-lxc plugin, which allowed Vagrant to provision lightweight Linux containers (LXC) instead of VMs.
There’s just something so satisfying about typing vagrant up and watching machines get spun up by Vagrant, and then seeing the green Ansible statuses slowly scroll by as the playbooks install the necessary software and libraries to run my code. Well, it’s satisfying unless I’m in a hurry and don’t want to wait 10+ minutes for all the machines to get provisioned. Or when I come back to a project months later and hit a red status due to a piece of the playbook now being broken. Or, in a deployment scenario, where I have to worry about external sources being unavailable (APT repositories, GitHub, RubyGems.org) or dependencies mutating between development testing and deployment time (e.g. new versions of APT packages becoming available, causing differing package versions to get installed on production).
Docker solves a lot of these problems. It simplifies development by making it fast and easy to spin up containers that are exact filesystem-level snapshots of production, typically differing only by environment variables or by config file difference (via mounted volumes). This same snapshotting mechanism makes it much less nerve-wracking to deploy to staging or production as well, as you are deploying the full snapshot at once. You don’t have to cross your fingers while APT updates packages, git does checkouts, or Bundler updates gems from RubyGems.org. Everything is already there in the Docker image.
Docker is especially appealing to me in the context of Rails deployments, since you have to do other things like compile assets for the asset pipeline or upgrade the Ruby interpreter version - things that are annoying to try and write in Capistrano or Ansible.
Note: You may have heard of the “vendor everything” approach to bundling gems for deployment, which advocates checking gem binaries into your source control. The benefit to that approach is that you no longer have to worry about RubyGems.org (or other gem sources) being down when you do deploys. The downside is that you add bloat to your source control by storing big fat binary files in it. Docker gives you the same benefit without corroding your source control. Win!
Creating Docker images: the Dockerfile
Terminology note: I was going to start by including my own simplified definitions of what Docker images and containers are, but the Docker website does a great job with these terms so check the links intead. But the main difference is that a container is an instantiated, running image, which can be be frozen back into an image (which will save all the filesystem modifications that have happened while it was running).
When creating your own Docker images, you will define the build instructions via a Dockerfile. A Dockerfile is a list of statements, executed imperatively, that follow a special DSL syntax. Each statement in the Dockerfile generates a new image that is a child of the previous statement’s image. You know what that creates? A directed acyclic graph (DAG) of images, not at all unlike a graph of git commits:
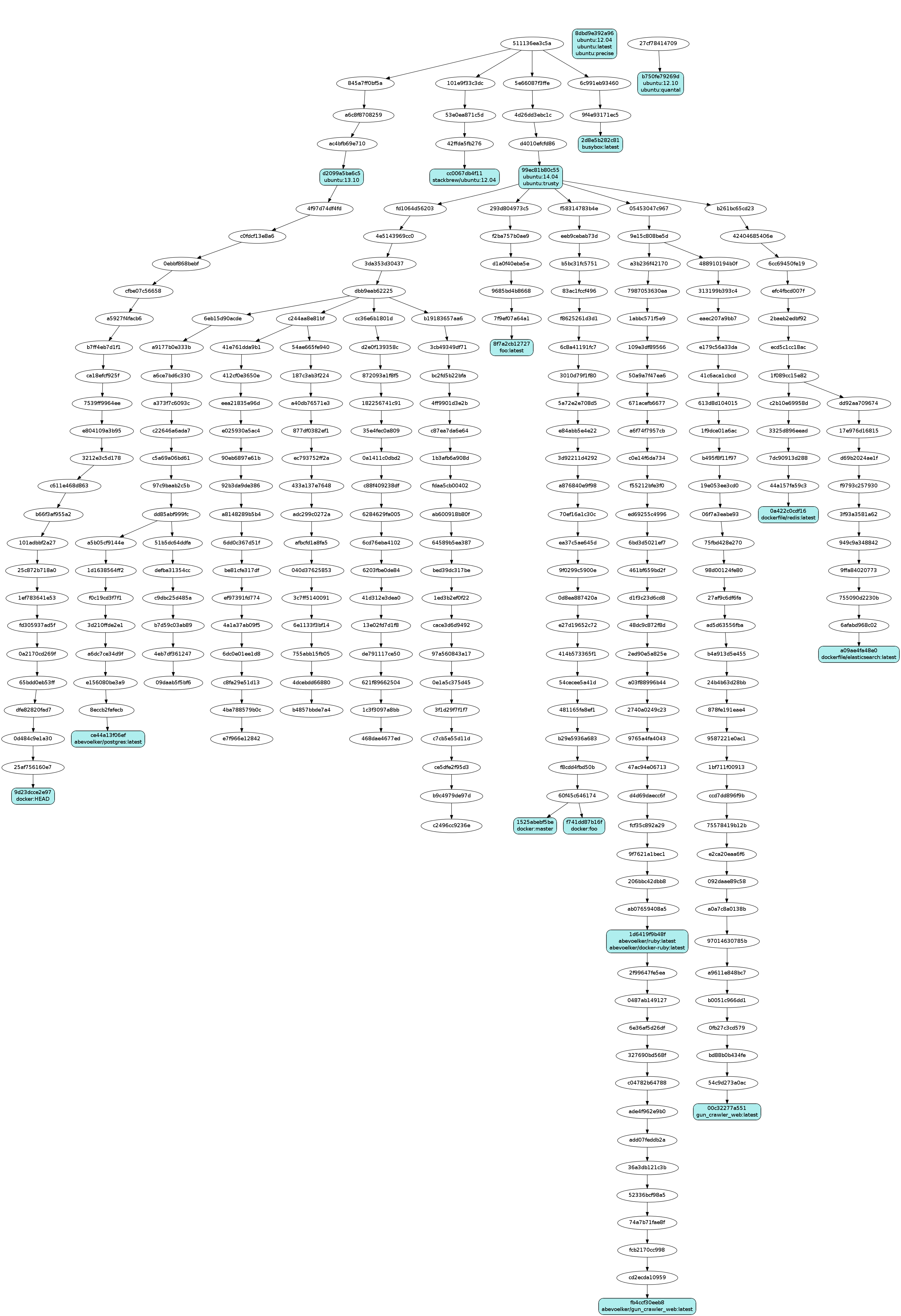
Note: Each blue image node in the graph above has a tag, very similar to a branch or tag in a git commit graph. This graph was generated with docker images --viz | dot -Tpng -o docker.png, if you want to look at the graph of Docker images on your machine. You can also see the graph in your console directly with docker images --tree
When building Docker images, Docker takes advantage of this graph structure to do caching. Each statement in a Dockerfile may be cached, and if the cache for that statement is invalidated, all of the child images (the proceeding Dockerfile statements) will need to be rebuilt as well.
As you may notice from the graph, when writing a Dockerfile it’s common to descend from an image (using the FROM statement) of a Linux flavor that you are familiar with. I use ubuntu:trusty as it’s what I’m familiar with - mainly so that I can use APT and custom PPAs to install packages. You can think of it in the context of Ruby as a sort of “subclass”-type inheritance.
If you get into Docker right now, expect to create your own Dockerfiles for services you need as there seems to be a dearth of good, easily reusable ones out there. When I was starting this post, you had to do a lot of digging through the Docker registry (formerly called the Docker Index) to find images to use (and you couldn’t even sort by stars!). So I’ve had to spend a lot of time porting over my own Ansible playbooks, which you can find on my Docker Hub page.
Now that they’ve launched “Docker Hub,” they have some images tagged as “official.” However, some of these “official” images don’t make it easy to see exactly how they are building the images (e.g. the official Postgres image), so I would steer clear for now. I imagine now that they’ve made it easier to use we will see some better images come out soon.
An example Rails app Dockerfile
Here’s an example Dockerfile of a Rails application that I’m working on right now:
FROM abevoelker/ruby
MAINTAINER Abe Voelker <[email protected]>
# Add 'web' user which will run the application
RUN adduser web --home /home/web --shell /bin/bash --disabled-password --gecos ""
# Separate Gemfile ADD so that `bundle install` can be cached more effectively
ADD Gemfile /var/www/
ADD Gemfile.lock /var/www/
RUN chown -R web:web /var/www &&\
mkdir -p /var/bundle &&\
chown -R web:web /var/bundle
RUN su -c "cd /var/www && bundle install --deployment --path /var/bundle" -s /bin/bash -l web
# Add application source
ADD . /var/www
RUN chown -R web:web /var/www
USER web
WORKDIR /var/www
CMD ["bundle", "exec", "foreman", "start"]
I’ll break up each piece and talk about it separately:
FROM
FROM abevoelker/ruby
As mentioned above, the FROM statement allows you to effectively chain your Dockerfile statements onto the end of a parent image. In this example, I am starting from an image I had created called abevoelker/ruby, which at the moment is tuned for my own use rather than reusability for others. You can check out the source code to see the goodies it contains (namely the latest MRI Ruby, nginx, git, a Postgres client, and Node.js for better execjs performance).
MAINTAINER
MAINTAINER Abe Voelker <[email protected]>
MAINTAINER sets the author metadata in the generated image. It’s just a nicety for people who might grab your image - not required.
ADD Gemfile and Gemfile.lock
ADD Gemfile /var/www/
ADD Gemfile.lock /var/www/
RUN chown -R web:web /var/www &&\
mkdir -p /var/bundle &&\
chown -R web:web /var/bundle
ADD copies files from where the Dockerfile is being built into the resulting image. ADD does not accept wildcards, so one cannot do ADD Gemfile*.
RUN executes commands in a new container. You will note that I am immediately chowning the files to my web user, because ADD gives the file root ownership (you will see this pattern a lot in Dockerfiles).
ADD gotcha: One thing that had tripped me up with ADD is that you cannot add files that exist above the Dockerfile’s directory. So you cannot do ADD ../some_file. There is a note on the ADD reference page if you want the technical details as to why.
bundle install
RUN su -c "cd /var/www && bundle install --deployment --path /var/bundle" -s /bin/bash -l web
This RUN statement generates the bundle that the Rails app will utilize. Note that I am storing the bundle in /var/bundle, outside of the application source directory where I put the Gemfiles earlier (/var/www). I’ll explain that shortly.
ADD application source
ADD . /var/www
RUN chown -R web:web /var/www
The full source of the Rails application gets added to /var/www. The reason this happens below the earlier Gemfile ADDs and the bundle install is twofold:
ADD . /var/wwwwill constantly be breaking thedocker buildcache, since any file change in the application’s directory will do it - even changing the Dockerfile itself. We don’t want to have to reinstall our gems every time we change a file - only if the Gemfile or Gemfile.lock changes.ADD . /var/wwwwill overwrite every file in/var/www. If we did ourbundle installto this same destination directory beforeADD, the bundle would have been wiped out. Therefore, I store the bundle in/var/bundleand the application source in/var/www.
USER
USER web
USER sets the user that all proceeding RUN statements will execute with, as well as the user that runs the image. It’s good security to run your Rails app as a non-privileged user.
WORKDIR
WORKDIR /var/www
WORKDIR sets the working directory for proceeding RUN, CMD, and ENTRYPOINT statements. I sometimes use it as a convenience so that I don’t have to dirty up the CMD statement with cd.
CMD
CMD ["bundle", "exec", "foreman", "start"]
CMD sets the default command that the image will run when started. You can have multiple CMD statements in a Dockerfile; the last one takes precedence (in this way inheriting images can override their parent’s CMD).
When running an image, you can override its baked-in CMD with your own command. For example, docker run -i -t ubuntu:trusty /bin/bash (the last argument to docker run, in this case /bin/bash, is the overridden command).
My example CMD statement starts foreman, which is adequate for development. It would probably be better to move each service in the foreman Procfile to their own supervisord configs, and have this CMD statement start up supervisord instead of foreman. Such an approach is common for running multiple processes in a Docker container and is production-safe.
Note: I mentioned that it is common to use supervisord to start up multiple processes in a Docker container. It is very important to note that Docker is not like a VM - the Docker container will only run the exact process that you tell it to run (that process in turn can spawn other processes). But there is no init process, no cron daemon, no SSH daemon, etc. It took me a little bit to understand this.
There is an image out there by Phusion that aims to replicate a basic running Linux system, but it seems to be frowned upon by the Docker devs I’ve seen in #docker as it goes against the intent of Docker and it can have wonky issues (for example, upstart scripts may behave weirdly due to not getting the correct signals they need to start).
It is also important to note that the process you start with your Docker container must run in the foreground, or Docker will think the container halted. Thus do not try to use /etc/init.d scripts as CMD arguments (instead, look at what those scripts are doing and unroll the daemonization).
An example Vagrantfile using the Docker provider
![]()
Vagrant 1.6 added support for Docker providers and provisioners. I’ve seen some people say that this will make it easier for people to learn Docker, but I disagree. Vagrant’s Docker provider DSL is a pretty thin façade over the Docker CLI, so you need to have a good handle on how Docker works before using it - otherwise you’re just dealing with another layer of indirection which will make things more confusing!
Anyway, here’s a Vagrantfile from a Rails app I’m working on called gun_crawler_web that corresponds to the Dockerfile from above:
# -*- mode: ruby -*-
# vi: set ft=ruby :
# Vagrantfile API/syntax version. Don't touch unless you know what you're doing!
VAGRANTFILE_API_VERSION = "2"
ENV['VAGRANT_DEFAULT_PROVIDER'] ||= 'docker'
Vagrant.configure(VAGRANTFILE_API_VERSION) do |config|
config.vm.define "postgres" do |postgres|
postgres.vm.provider 'docker' do |d|
d.image = 'abevoelker/postgres'
d.name = 'gun_crawler_web_postgres'
d.ports = ['5432:5432']
end
end
config.vm.define "elasticsearch" do |elasticsearch|
elasticsearch.vm.provider 'docker' do |d|
d.image = 'dockerfile/elasticsearch'
d.name = 'gun_crawler_web_elasticsearch'
d.cmd = ['/elasticsearch/bin/elasticsearch', '-Des.config=/data/elasticsearch.yml']
d.env = {
'ES_USER' => 'elasticsearch',
'ES_HEAP_SIZE' => '512m'
}
end
elasticsearch.vm.synced_folder "docker/elasticsearch", "/data"
end
config.vm.define "redis" do |redis|
redis.vm.provider 'docker' do |d|
d.image = 'dockerfile/redis'
d.name = 'gun_crawler_web_redis'
d.cmd = ['redis-server', '/data/redis.conf']
end
redis.vm.synced_folder "docker/redis", "/data"
end
config.vm.define "web" do |web|
web.vm.provider 'docker' do |d|
d.image = 'abevoelker/gun_crawler_web'
d.name = 'gun_crawler_web'
d.create_args = ['-i', '-t']
d.cmd = ['/bin/bash', '-l']
d.remains_running = false
d.ports = ['3000:3000']
d.link('gun_crawler_web_postgres:postgres')
d.link('gun_crawler_web_elasticsearch:elasticsearch')
d.link('gun_crawler_web_redis:redis')
end
web.vm.synced_folder ".", "/var/www", owner: 'web', group: 'web'
end
end
As you can see, this configuration defines four containers that make up my application. One for Postgres, one for Redis, one for Elasticsearch, and of course one for my Rails application.
Let’s look at each config section so we can understand what’s going on.
Postgres container
config.vm.define "postgres" do |postgres|
postgres.vm.provider 'docker' do |d|
d.image = 'abevoelker/postgres'
d.name = 'gun_crawler_web_postgres'
d.ports = ['5432:5432']
end
end
The first line:
d.image = 'abevoelker/postgres'
is obviously referencing the image that will be used to start the container. If the image doesn’t exist locally (if you didn’t docker build -t or docker pull it), then it will be pulled down from the Docker registries you have defined (by default, docker uses the public Docker Hub registry).
d.name = 'gun_crawler_web_postgres'
This assigns a unique name to the container. This is a convenience so that when you are using the Docker CLI, you don’t have to use the hash ID to reference it. This will be important later to the Rails application container definition.
d.ports = ['5432:5432']
This forwards ports port 5432 from the container to port 5432 on the host machine. The only reason I do this is so I can use pgAdmin on my host machine to inspect the development database. I do not need to expose the port in order to connect to it from the Rails application (as I’ll show later).
Equivalent Docker CLI
Remember when I said Vagrant was a thin façade over the Docker CLI? If you didn’t have Vagrant, you can easily run the container yourself the same way via the Docker CLI:
docker run -d -name gun_crawler_web_postgres -p 5432:5432 -t abevoelker/postgres
Note: To list all containers running on your host machine, use docker ps. To list all containers (included stopped ones), use docker ps -a.
Elasticsearch container
config.vm.define "elasticsearch" do |elasticsearch|
elasticsearch.vm.provider 'docker' do |d|
d.image = 'dockerfile/elasticsearch'
d.name = 'gun_crawler_web_elasticsearch'
d.cmd = ['/elasticsearch/bin/elasticsearch', '-Des.config=/data/elasticsearch.yml']
d.env = {
'ES_USER' => 'elasticsearch',
'ES_HEAP_SIZE' => '512m'
}
end
elasticsearch.vm.synced_folder "docker/elasticsearch", "/data"
end
The new config options are:
elasticsearch.vm.synced_folder "docker/elasticsearch", "/data"
As you can imagine, this mounts the local docker/elasticsearch directory into the container as /data (this is a Docker volume). A common use case for this is if you have a configuration file you need to make available to the service.
d.cmd = ['/elasticsearch/bin/elasticsearch', '-Des.config=/data/elasticsearch.yml']
This is the command used to start the image (it overrides the image’s default CMD). Note we are passing it a configuration file that exists in the /data volume we mounted.
d.env = {
'ES_USER' => 'elasticsearch',
'ES_HEAP_SIZE' => '512m'
}
As you may have guessed, this sets the $ES_USER and $ES_HEAP_SIZE Unix environment variables in the container to values we specify.
Equivalent Docker CLI
docker run -d -v docker/elasticsearch:/data -name gun_crawler_web_elasticsearch --env ES_USER=elasticsearch --env ES_HEAP_SIZE=512m -t dockerfile/elasticsearch /elasticsearch/bin/elasticsearch -Des.config=/data/elasticsearch.yml
Redis container
config.vm.define "redis" do |redis|
redis.vm.provider 'docker' do |d|
d.image = 'dockerfile/redis'
d.name = 'gun_crawler_web_redis'
d.cmd = ['redis-server', '/data/redis.conf']
end
redis.vm.synced_folder "docker/redis", "/data"
end
Nothing new here.
Equivalent Docker CLI
docker run -d -v docker/redis:/data -name gun_crawler_web_redis redis-server /data/redis.conf
Rails application container
config.vm.define "web" do |web|
web.vm.provider 'docker' do |d|
d.image = 'abevoelker/gun_crawler_web'
d.name = 'gun_crawler_web'
d.create_args = ['-i', '-t']
d.cmd = ['/bin/bash', '-l']
d.remains_running = false
d.ports = ['3000:3000']
d.link('gun_crawler_web_postgres:postgres')
d.link('gun_crawler_web_elasticsearch:elasticsearch')
d.link('gun_crawler_web_redis:redis')
end
web.vm.synced_folder ".", "/var/www", owner: 'web', group: 'web'
end
d.image = 'abevoelker/gun_crawler_web'
This is not a new option, however I want to point out that I actually prefer to build the image manually rather than let Vagrant do it. Why? Because on my machine I don’t see the Docker build output when Vagrant does it - I just get a black screen until it is all finished, which is not very useful when developing.
So before I do vagrant up, I build my Rails application Docker image locally with docker build -t abevoelker/gun_crawler_web ..
d.create_args = ['-i', '-t']
These are extra arguments passed to docker run. These arguments ensure that the container is ran interactively, so that we can attach to the shell properly (more on that later).
d.remains_running = false
Vagrant apparently errors if the container stops; since we will be occasionally halting the container when we detach from it we don’t want Vagrant to throw a fit.
d.ports = ['3000:3000']
I forward the common Rails development server port so that on my host machine browser I can visit http://localhost:3000. Once I harden this image for staging/production, I will probably be EXPOSEing port 80, so I expect this config to change soon.
d.link('gun_crawler_web_postgres:postgres')
d.link('gun_crawler_web_elasticsearch:elasticsearch')
d.link('gun_crawler_web_redis:redis')
This is an extremely important concept called container linking. We link the previous three containers into the application container, which allows the application container to access the exposed ports and see environment variables of the linked containers. When linking, the form is linked_container_name:alias. The alias bit is important because environment variables exposed in the container will be prefixed with the alias name.
For example, in order to connect to the Postgres database using the above linking definition, I’ve modified my config/database.yml file like so (it takes advantage of Rails evaluating ERB in this file):
# config/database.yml
postgres_defaults: &postgres_defaults
adapter: postgresql
encoding: utf8
port: 5432
host: <%= ENV['POSTGRES_PORT_5432_TCP_ADDR'] %>
username: <%= ENV['POSTGRES_ENV_USERNAME'] %>
password: <%= ENV['POSTGRES_ENV_PASSWORD'] %>
pool: 5
development:
<<: *postgres_defaults
database: gun_crawler_development
test:
<<: *postgres_defaults
database: gun_crawler_test
$POSTGRES_ENV_USERNAME and $POSTGRES_ENV_PASSWORD are generated by Docker from environment variables exposed in the abevoelker/postgres image Dockerfile (via ENV USERNAME / ENV PASSWORD).
$POSTGRES_PORT_5432_TCP_ADDR is automatically generated by Docker from the exposed ports defined in the abevoelker/postgres image Dockerfile (via EXPOSE 5432).
d.cmd = ['/bin/bash', '-l']
This isn’t a new option, but note that we are running bash rather than the Rails server or foreman. Basically, after I do vagrant up, I then run docker attach gun_crawler_web, and that attaches me to this interactive bash shell (note you might have to hit enter after running that command to redraw the shell).
From here I’m free to run whatever commands one normally runs when in development, like rake db:setup, rake db:migrate, rails c, rails s, etc. I think this is a lot better way of doing things than spawning a bunch of different containers for every little command, which I’ve seen some tutorials do.
Equivalent Docker CLI
docker build -t abevoelker/gun_crawler_web .
docker run -i -t -v .:/var/www -name gun_crawler_web --link=gun_crawler_web_postgres:postgres --link=gun_crawler_web_elasticsearch:elasticsearch --link=gun_crawler_web_redis:redis /bin/bash -l
Putting it all together
So basically, from scratch, these are the commands I run from a freshly-checked-out Rails application:
docker build -t abevoelker/gun_crawler_web . # OR docker pull abevoelker/gun_crawler_web
vagrant up
docker attach gun_crawler_web
As I’m working, if I detach from the bash shell, the Docker container is halted. I can bring it back up with either vagrant up web or docker start gun_crawler_web, and then re-attach with docker attach gun_crawler_web.
If I ever have to do a full rebuild of the Docker image, I just do:
vagrant destroy gun_crawler_web
docker build -t abevoelker/gun_crawler_web .
vagrant up web --provider=docker
If there is interest, I could make a demo Rails application with a Dockerfile and Vagrantfile in a ready-to-go package for trying this out. Let me know in the comments if that’s something you’d be interested in.
Next step: deployment

So far, I’ve only updated my development environment to use Docker. I have yet to deploy to a remote staging/production environment. I have some ideas, but have yet to try them out.
Therefore my next article will be focused on Rails deployment using Docker. I plan on primarily using Ansible for this, using its Docker module.
Some questions/notes I’m still thinking about:
- How to ensure container volumes persist - use linked persistent containers or expose host filesystem?
- Is there a good way to handle rollbacks, à la Capistrano’s
cap deploy:rollback? - Some things will still need to be done in a deploy playbook besides managing Docker containers, e.g.
rake db:migrate - What makes a good host system OS - would it make sense to use CoreOS? Can we benefit from etcd and confd?
- Is there a good way to do zero-downtime deploys without adding excessive complexity?
Addendum: Docker gotchas
And now VOLUME is giving me the middle finger on permissions. Surprising how fickle Docker is for how supposedly close to 1.0 it is.
— Abe Voelker (@abevoelker) May 31, 2014When I first started with Docker, I was kind of surprised to run into some issues and rough edges since I was using the 1.0 release candidate (0.10). However, the Docker team (and other people) have been very responsive in IRC (#docker on Freenode), GitHub issues, and even just picking up mentions of Docker on Twitter. If you run into any issues they will help you or get it fixed straight away.
Some issues or surprises I’ve ran into that might be useful to you:
- When building a lot of images locally, Docker consumes a lot of disk space by leaving orphaned images (see graph above) and stopped containers around. I actually ran out of disk space a couple times due to this (it was using 46GiB at the time). From idling the #docker IRC a while, this isn’t an uncommon problem for people to have. It would be nice if there was an equivalent to git’s
git gcto clean up orphaned images, but until then the workarounds are to periodically:- Delete untagged images with
docker rmi $(docker images -a | grep "^<none>" | awk '{print $3}') - Delete stopped containers with
docker rm $(docker ps -a -q)
- Delete untagged images with
- The
USERstatement in a Dockerfile does not apply toADDstatements that follow it -ADDalways sets the file owner to root.- If you want to
ADDfiles that should belong to a specific user, you should put theADDstatement above theUSERstatement and immediately follow it with aRUN chownstatement to modify the ownership. - There is an open issue on this (what I consider) surprising behavior, however the Docker maintainers that have responded don’t seem too enthusiastic on changing it.
- If you want to
- Each
RUNstatement in a Dockerfile runs in a different container than the previous one. Therefore, you cannot do something likeRUN /etc/init.d/some-serviceand then on the next line have anotherRUNstatement that expects that service to be running. I ran into this with my Postgres image. The simple solution is just to chain the statements with&&(e.g.RUN /etc/init.d/some-service && your-command). As a bonus you will create less images/containers as well when building your Dockerfile. - On Docker 0.11 and below, there was an issue I found with
VOLUMEchanging permissions on exposed directories.- This has been fixed in 0.12, so if you are on the latest Docker you won’t run into this.